
Visualizing Paired Image Similarity in Transformer Networks
Samuel Black
Abby Stylianou
Robert Pless
Richard Souvenir
Published at WACV 2022
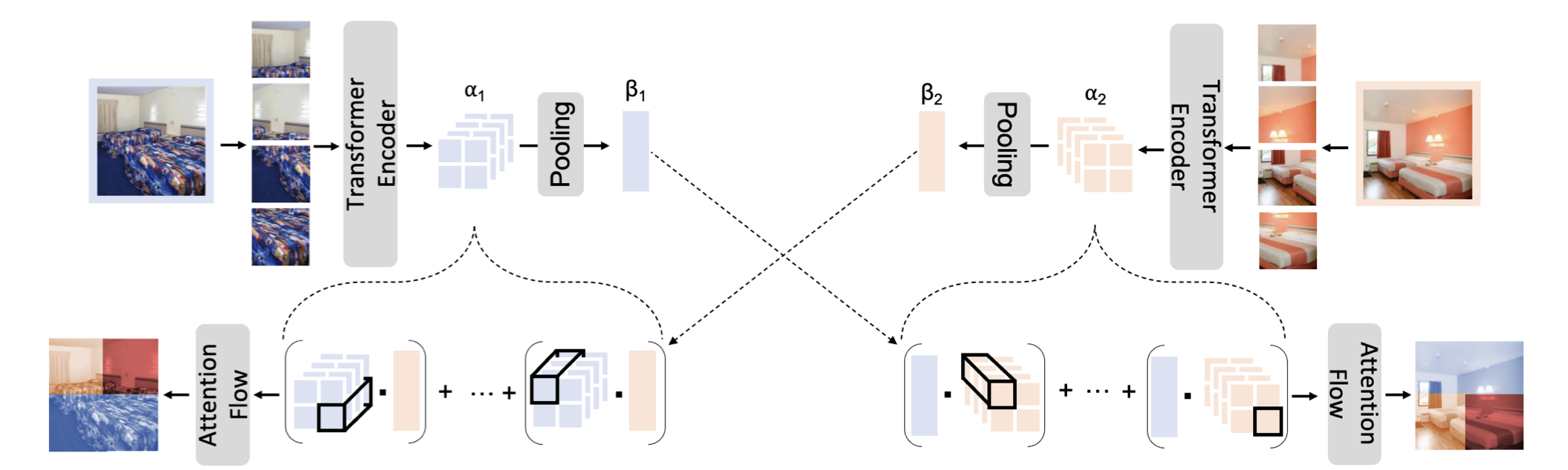
Transformer architectures have shown promise for a wide range of computer vision tasks, including image embedding. As was the case with convolutional neural networks and other models, explainability of the predictions is a key concern, but visualization approaches tend to be architecture-specific. In this work, we introduce a new method for producing interpretable visualizations that, given a pair of images encoded with a Transformer, show which regions contributed to their similarity. Additionally, for the task of image retrieval, we compare the performance of Transformer and ResNet models of similar capacity and show that while they have similar performance in aggregate, the retrieved results and the visual explanations for those results are quite different.
Examples of paired similarity maps generated with our method:

@inproceedings{black2022visualizing,
title={Visualizing Paired Image Similarity in Transformer Networks},
author={Black, Samuel and Stylianou, Abby and Pless, Robert and Souvenir, Richard},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
pages={3164--3173},
year={2022}
}